How the Magic of IBLTs Could Boost Bitcoin’s Decentralization
Bitcoin requires decentralization of miners (or mining pools) and full nodes to achieve what some consider its core property: censorship resistance. As such, the block-size dispute represents a trade-off. Bigger blocks allow for more transactions on the Bitcoin network, but take more time to propagate, favoring larger miners and pools, while the increased data transmission disincentivizes users to run full nodes.
Fortunately, there are proposals to increase Bitcoin’s efficiency that reduce the risk of bigger blocks. One of the most promising innovations in this regard, are Invertible Bloom Lookup Table, or IBLTs. First introduced by Bitcoin XT and Bitcoin Core developer Gavin Andresen, this idea was picked up and is currently worked on as a side-project by Linux veteran and Blockstream’s Lightning Network developer Paul “Rusty” Russell.
“If we can make this work, it means less bandwidth requirements and less block data, which should be good for network health all over,” says Russell.
Redundancy
So what problem do IBLTs solve?
Typically, all Bitcoin transactions are transmitted from node to node over the peer-to-peer network, to be stored by the mempools (the record of unconfirmed transactions) of individual nodes. When a miner finds a block, it includes (some of) these transactions in that block, and subsequently transmits this block over the same peer-to-peer network. Of course, this means that all transactions in the block are effectively sent over the network twice: once as a transaction, and once as part of a block.
Speaking to Bitcoin Magazine, Russell explained:
“We’ve got redundancy in blocks. Most nodes already know some of the content in that block; they have already seen it. If we can optimize that, we can speed up block transmission. That decreases centralization pressure because miners can get their blocks out faster, while the network works better … it’s all good.”
The Magic of IBLTs
The main problem – the reason we need IBLTs to solve this problem (rather than a straightforward compression algorithm) – is that the set of transactions included in blocks is often not exactly identical as those stored by the mempools of all individual nodes; the biggest difference being the latest transactions transmitted over the network before the block was found. Moreover, the mempools of all individual nodes usually differ from each other a bit, too. This makes it hard to know which transactions a miner included in the new block, without seeing the whole block.
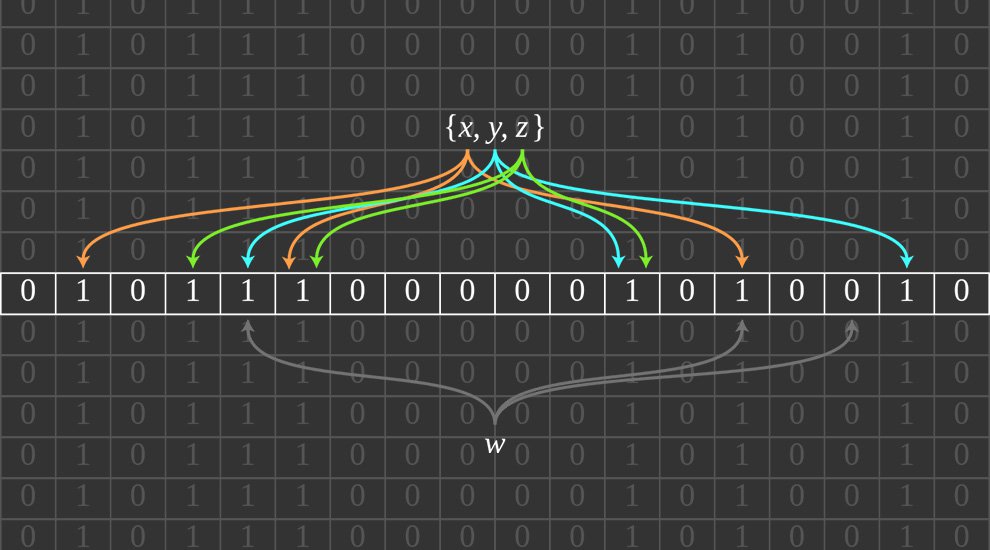
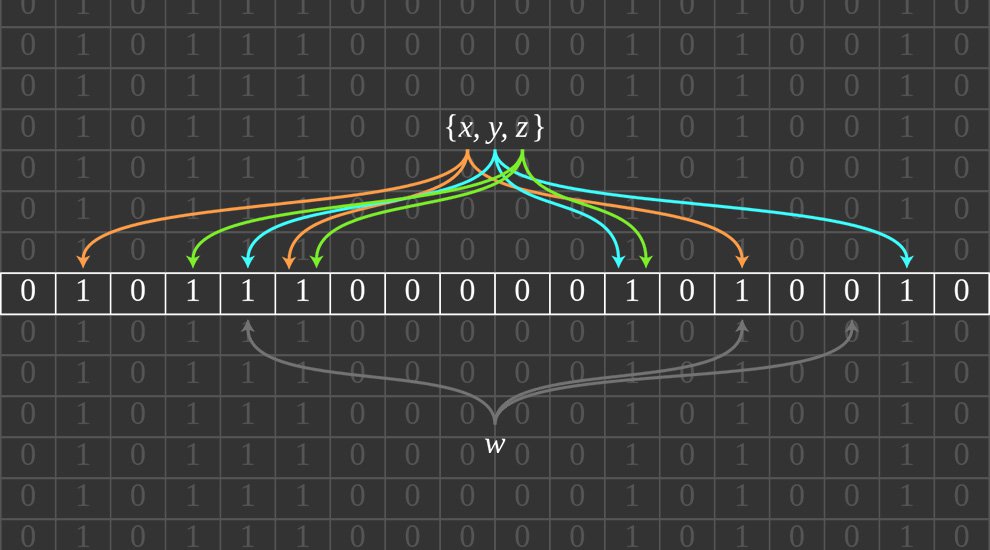
That’s where IBLTs come in. IBLTs combine several mathematical tricks to enable set reconciliation. As such, they basically allow for two slightly different mempools to be compared and harmonized, without actually needing both mempools in full.
This works as follows:
At first, all transactions included in a block are written into a table, where each transaction starts at a different spot in that table. However, there are many more transactions than there is room in the table, so the result is hopelessly overlapping. This makes the IBLT very compact, but also unreadable and undecipherable for anyone who doesn’t have access to any transaction data himself.
Anyone who does have transaction data, however, can compare the overlapping transaction data in the IBLT to his own transaction data by filling up an IBLT with his own transactions using similar logic. If both IBLTs end up looking exactly the same, it means all transactions match exactly.
But even if the IBLTs do not end up looking exactly the same, this can still be helpful, as long as the sets of transactions are fairly similar. In that case, the IBLTs can be compared in such a way that all identical transactions cancel each other out. The “leftovers” in the IBLT, then, can often be used to reconstruct the missing transactions.
So rather than needing to transmit full blocks over the peer-to-peer network, nodes can transmit the much smaller IBLTs instead. This requires less data to be sent around and is much faster.
Efficiency
And it gets better. In Russell’s design, not even all of the transactions included in new blocks need to fit in the IBLTs. Instead, connected nodes on Bitcoin’s peer-to-peer network fine tune which transactions to send to peers. This could increase propagation time and decrease data usage even more.
“Gavin’s original idea was that the miner would produce the IBLT, and send every node on the network the same one,” Russell said. “But when we started playing with the concept, it turned out it’s very fast to generate IBLTs. So why not have every node do it? Generate IBLTs per peer, because each node has a much better idea of how close its mempool has been to a peer; they’re sending this stuff back and forth all the time.”
Moreover, connected nodes can continually learn to understand each other’s behavior. So once a node receives an IBLT from the network, and constructs a valid block out of it, it knows how many transactions it was missing. Additionally, it learned over time how many transactions his peer typically differers from him. That difference – the transactions it had to construct plus the usual difference between the two peers – is what the node will include in the IBLT and send to its peer.
As such, the IBLT system can improve over time, limiting the amount of data to transmit over the network to the bare minimum.
“The IBLT must roughly be twice the data size of the transaction difference,” Russell explained. “So out of all the transactions one node didn’t know were in a block, plus the transactions that node thought were in the block but weren’t… basically double that, and that’s how big the IBLT needs to be. So if the differences are small, it will work really well.
“Ideally, if we can cram this thing into two IP packets,” he said. “We are lightning fast.”
Specific details of IBLTs and Bitcoin can be found on Russell’s blog and Andresen’s GitHub contribution.
The post How the Magic of IBLTs Could Boost Bitcoin’s Decentralization appeared first on Bitcoin Magazine.

